Parameters of a model you selected in the MODEL tab are listed in the RUN tab > Settings, see image below. Each parameter has two attributes: an initial value and a constraint.
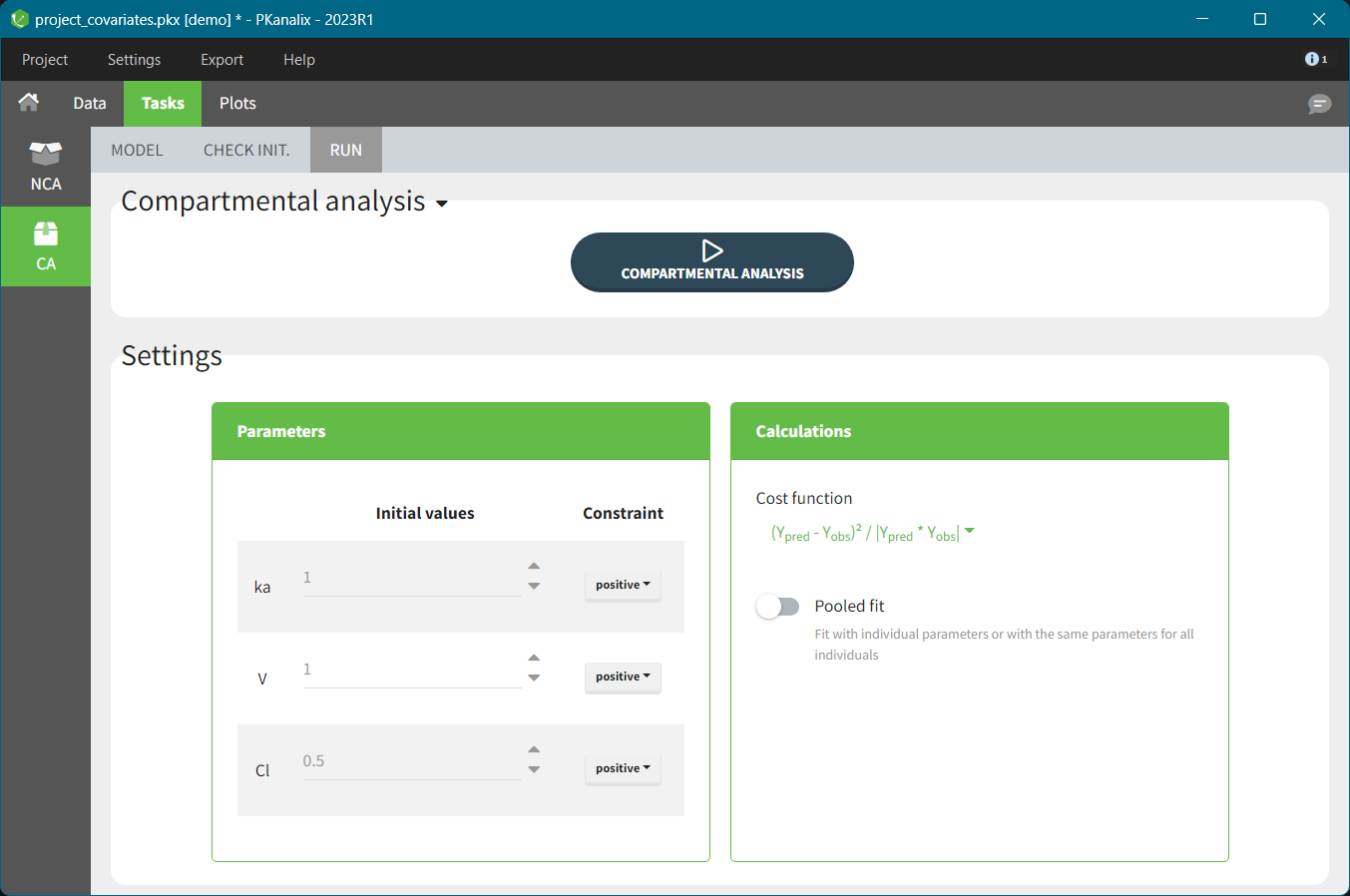
Constraint sets a range of allowed values for selected parameter during estimation (and as initial values). There are three types of constraints:
- none: a parameter is not constraint and its value can be from minus to plus “infinity” (in practice its minus or plus 10e16),
- positive: (default option) a parameter is strictly greater then zero,
- bounded: a parameter is strictly inside a bounded interval which limits you can specify manually.
You can set an initial value of a parameter manually or using the auto-initialization algorithm. Selection of “good” initial values – capturing the characteristic features of a selected model (e.g two slopes on log scale for a 2-compartment model) – is important during the estimation of parameters with the optimization algorithm. It can help to avoid local minima during the optimization process and decrease the runtime of the algorithm.
CHECK INIT.
In the Tasks tab of the CA section there is a dedicated sub-tab CHECK INIT. to help you in the initialization of parameters. The goal of the CHECK INIT. sub tab is to:
- Visually check parameters initialization. It displays the model predictions obtained with the initial model parameters values and the individual designs (doses and regressors) for each individual together with the data points.
- Help finding “good” initial values: manually or with the auto-init function.
CHECK INIT. tab in PKanalix uses the same auto-init algorithm and has the same features as CHECK INIT. in Monolix.
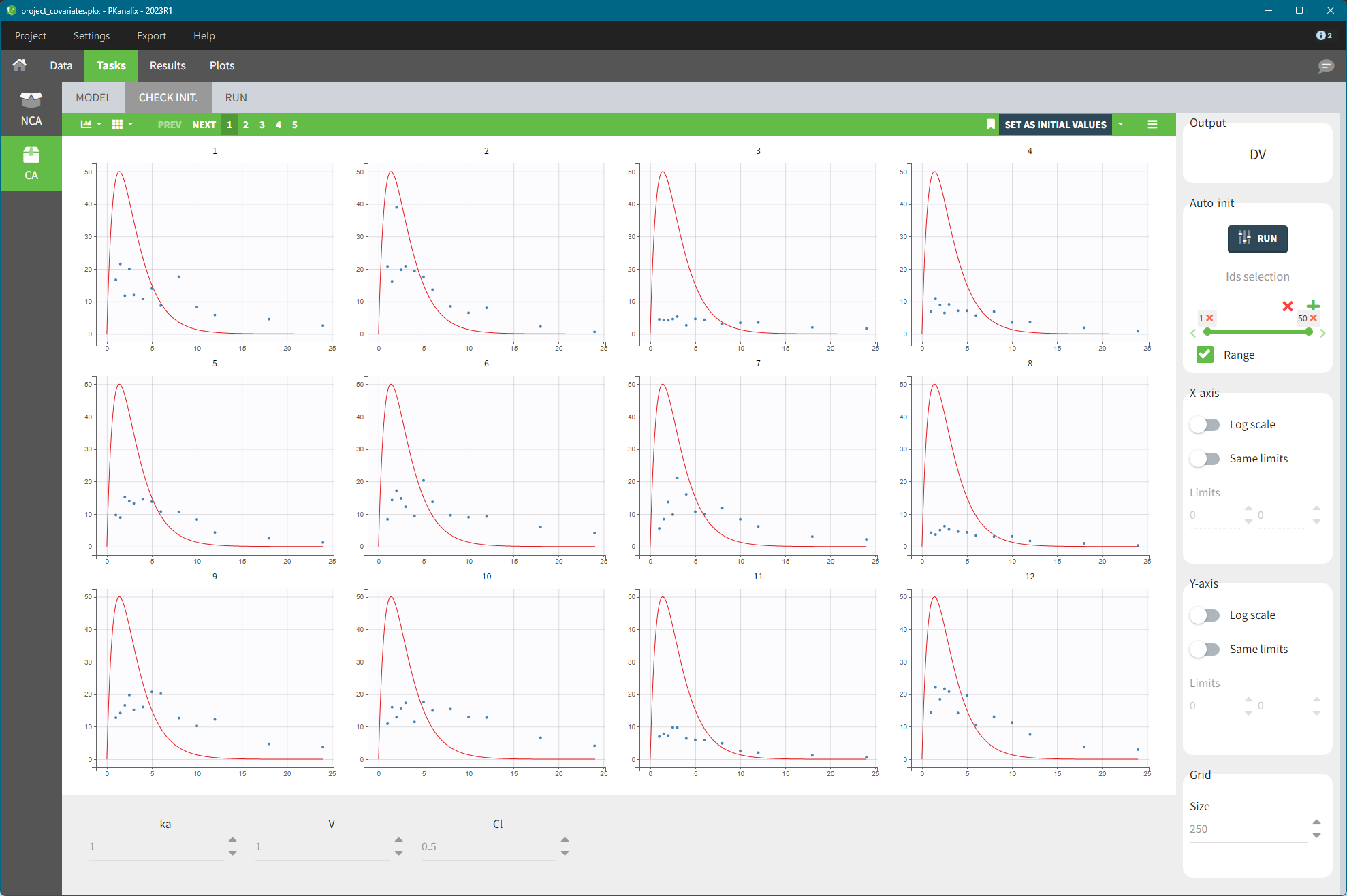
- You can modify the initial values of the parameters, shown on the bottom of the screen, manually by typing new values or using the auto-init algorithm – click the button RUN in the right panel.
- Switch toggle buttons in the X-axis and Y-axis sections to set log-scale and to apply the same limits for all individual plots. It gives a better comparison between the individuals.
- If there are not enough points for the prediction (e.g. there are a lot of doses ), change the grid size by increasing the number of points (last section in the right panel).
IMPORTANT: Click on the “SET AS INITIAL VALUES” button on the top of the plot to save the initial values for the optimization step.
If there are several observation types which obs-ids have been mapped to model outputs (for example a parent and a metabolite, or a PK and a PD observation), then switch the plots between them in the “Output” section on the top-right corner, see figure below.
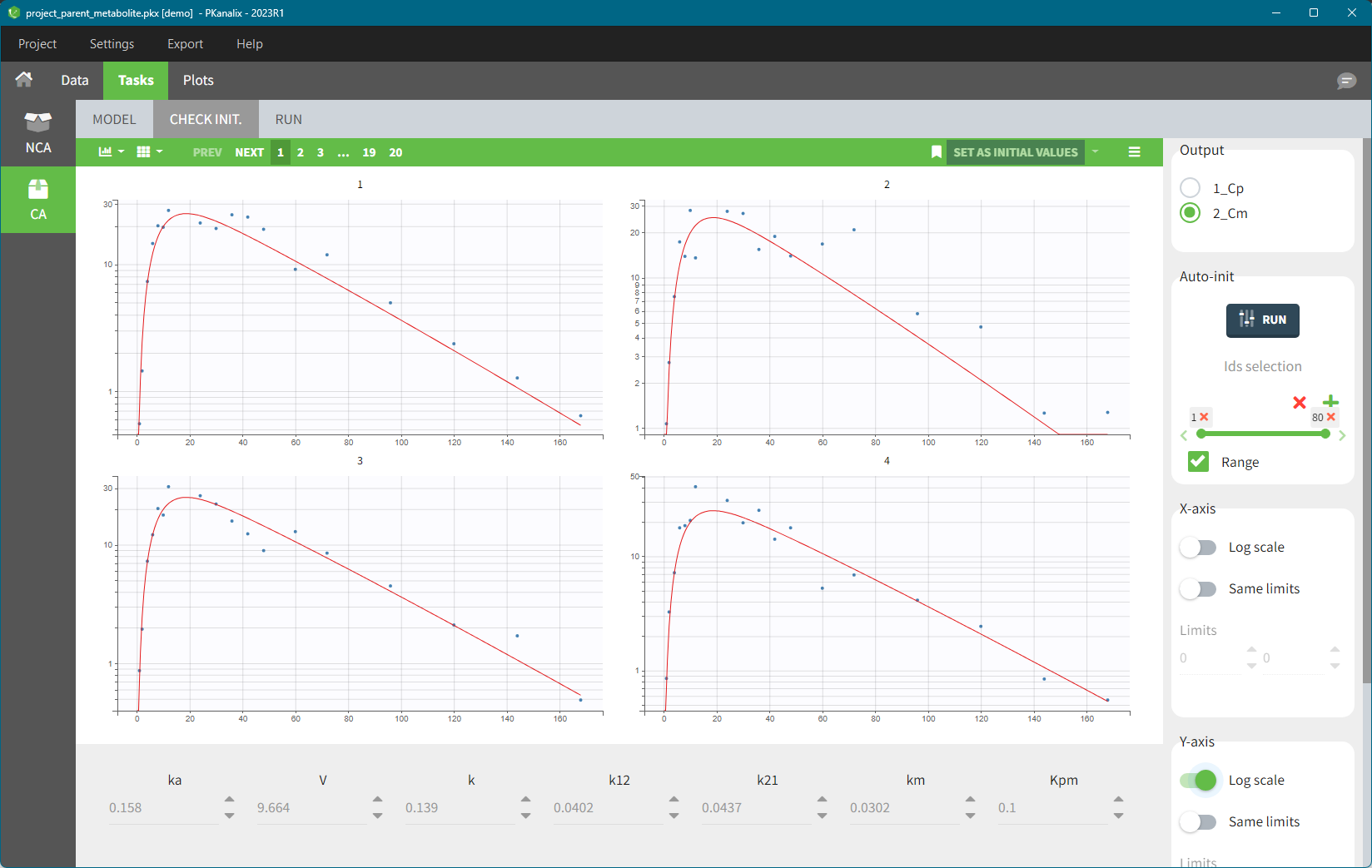
Reference in the “check initial estimates”
The following video describes how to use the Reference option and when it can be helpful. It uses an example in Monolix, but this feature works in the same way in PKanalix.
[/vc_column_text][/vc_column][/vc_row]
Adding a reference helps to see better how changing parameter values impacts the prediction. To add a reference click on the icon next to “Set as initial values” button. It saves the current curve (i.e. current parameters values) as a reference and adds it to the list on top of the right panel, see below. The solid red curve corresponds to the current set of parameters (displayed at the bottom), while the dashed one corresponds to the reference. At any time, you can restore the reference as the current curve (green arrow next to the reference curve name), delete the reference (red cross) or delete all references by clicking on the trash icon above the list.

Auto – init: Automatic initialization of the parameters
PKanalix has an automatic algorithm for the initialization. It is in the right panel in the Auto-init section and you can lunch it by clicking on the button RUN. The following video describes how it works using an example in Monolix.
https://youtu.be/IULGI9Wqahg[
After clicking on the button RUN, PKanalix computes initial model parameters that best fit the data points using a polled fit approach, starting from parameter values currently used in the panel at the bottom. By default, the algorithm uses all individual data from all observations mapped to a model output. You can change the set of individuals in the “Ids” selection panel just below the RUN button.
The algorithm is a custom optimization method, on the pooled data. The purpose is not to find a perfect match but rather to have all the parameters in the good range for starting the Nelder-Mead optimization on each individual.
- While auto-init is running, the pop-up shows the evolution of the cost of the optimization algorithm over the iterations. Stop the algorithm at any time, e.g. if you see that the cost has decreased sufficiently and you want to check the parameter values.
- Note that the more individuals you select, the longer the run will take.
- Selecting one or few individual that show clearly model characteristics (eg a third compartment, a complex absorption) can help the auto-init algorithm to find set of parameters that is sensitive to specific model features.
After running the auto-init, PKanalix interface updates automatically parameter values and plots with new predictions. To use these parameters as initial values in the optimization process, you click on the button “SET AS INITIAL VALUES”.
Note that the auto-init procedure takes into account the current initial values. Sometimes the auto-init might give poor results. To improve it change manually the parameter values before running the auto-init again.